最近十年的ML方法: ensemble
ensemble methods 把多個independent weak classifiers的預測結果透過"majority voting"節合在一起。所謂的weak classifier就是預測結果至少比random好一些,但也僅只於此。一組training data怎麼產生多個independent weak classifiers? 以下3個strategies可以利用:

Boosting
假設某個training data set可以每次透過modification產生一組新的samples,用不論何種方法來train某個classifier Gm(x):
最後把這些classifiers依據performance來給予相對應的weight,然後計算weight sum (就是所謂的民主投票,majority voting....):

關鍵點怎麼modify training samples? 根據每一次找出的Gm(x),我們都可以先找出預測錯誤的samples,例如以下黑圈是G1(x)找出錯誤的:

所以要modify這些error samples,給他們某種更大的weight wi(怎麼計算?),用來train G2(x),這會讓G2在focus在predict這些samples時更多著墨 (how?)。
原本的prediction error rate是數人頭算平均:

但是weighted (modified)sample的prediction error rate要把算weighted average:

之前說的alpha就根據errm來算出:

Adaboost 演算法
如下:
舉例來說明會比較簡單。假設有某個簡單的binary classifier:

xi 是j-dimensional feature vector,而classifier是利用某個threshold t來判斷vector i中的某個jth element 是否該判斷成1 or -1 class,基本上是一個很簡單的classifier(本來要打很低能,這個classifier稱為stump)。
現在如果d = 10,有2000個training samples +10000個testing samples,來比較一下adaboost是否有所改善?
下圖是random classifier, stmup classifier boosted, 以及244-node decision tree的error rate比較,random classifier error rate可以預見會是0.5,而完整的244-node decision tree error rate還有0.24,可是stump classifier經過400個iterations之後可以把error rate降低到0.05以下!
三個臭皮匠 勝過豬哥亮?!

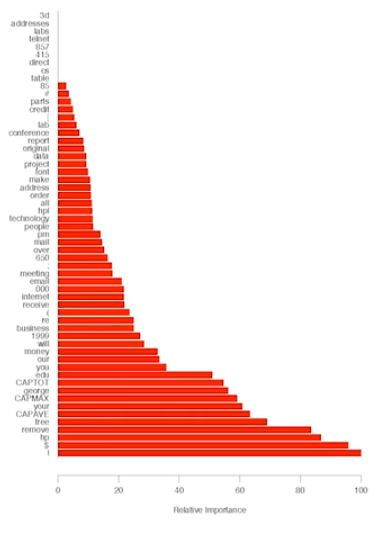
事實上adaboost是一種選擇最優feature的實驗過程,選出較好的feature時,就給大的weight,這在最後combined classification會有明顯的貢獻。例如以下是某個email spam classifier的每個feature以及其adaboost alpha weights:
Bootstrapping & Bagging
又是惱人的名詞解釋。bootstrapping是一種sampling方式,而boosting就是靠bootstrapping來從training data中resample並且modify成新的training sample給下一個training iteration使用。
這邊所謂的modify strategy就是randomly distort data by resampling
Bagging是個複合字 = Bootstrap Aggregation。簡單說很類似boosting:

詳情還是請洽ML course!!!!!!!!!!!!!!!!!!!!!
沒有留言:
張貼留言