why Conc Tree?
之前提到,我們採用intermediate data structure來解決"efficient" combining問題。但是另一個可能就是,是否存在本來就是efficient combine operation (concatenate/union)的data structure?
List & Tree
scala list定義如下:(又稱為conc list)

list天生就是sequential,但是tree可以parallel:

我們可以用以下的方法來implement tree parallel filter:

問題是這樣的implementation不能給出一個適合parallelization的balanced tree, 中間的tree不是optimal height因為Leaf case仍會return Empty,如果修改不讓Leaf case return Empty的話,會變成最右邊那樣,像list而非tree,非常不balanced:

Conclist - balanced tree
為了達成balance,我們要另一個data structure Conc,trait 定義如下:

level :就是height
size: 就是這個tree有幾個elements
以下為Conc trait可能的concrete implementation:

conc tree有invariants必須要遵守:
1. <> (inner node) 不能有Empty child
2. <>的左右children的level差 <= 1,為了要達成balanced tree。以下這個tree就違反了invariant 2:
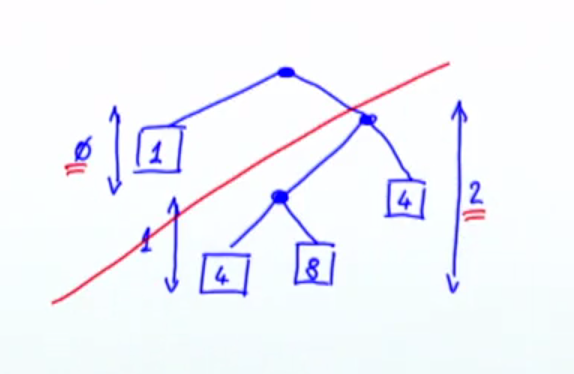
以下這個才符合variant 2:

所以invariant 2 保證conc tree的operations至少能在O(log n)完成。
我們可以定義一個 <> method,用來當作concatenation (注意這根constructor 名字一樣):

這method裡面先檢查了invariant 1,然後真正做balancing (滿足invariant 2)的是concat method,concat method就檢查invariant 2,如果滿足的話就new 一個inner node <>當成parent node:

否則的話,tree xs和tree ys必須要做combination。
先假設xs的height = d,ys的height = e <= d-2 。
所以要看xs的trees的leaning狀況(哪邊的tree較深)如何來決定要怎麼merge。
1. xs is left-leaning (左邊subtree較深)
注意右邊subtree最多高度d-1 (否則不會通過invariant 2)。則我們就把右邊的subtree與ys concat recursively,最後在形成一個parent node連接兩者:

2. xs is right-leaning,右邊的subtree比較長:
注意下圖把xs的右邊subtree的左右children subtree的可能深度配對都列出來了,分別是:
(d-2, d-2)
(d-3, d-2)
(d-2, d-3)
可能的combination結果如下圖:(沒有完全列出來,看code吧):


重點是 這個combination有達到我們要的O(log(n) + log(m) )嗎?!
注意此演算法的base case是某個兩者高度差 < 某值,所以recursion深度取決於O(xs_height - ys_height) < O(logn),可以說Conc tree是符合parallel combiners需求的data structure。
Conc tree to implement combiner!
Conc tree concatenation兩個tree可以有O(h1-h2),但是我們還需要constant time append operation,才能實現"efficient" parallel combiner,所謂efficient就是 O(logm + logn),n = combiner1 #elements, m = combiner2 #elements。
combiner trait的append就是 += method,假設我們用conc tree來當作combiner的instance variable xs:

我們知道至少要O(log n) time來做append,但是有沒有辦法constant time?
事實上是有ㄟ!
不過要loose Conc tree invariance 2: 仿造 <> node,定義一個Append node:

但是不限定append node的左右children的高度差!所以以下的subtree 是合法的:

所以append很快,可以是O(1),因為只要把append node的children pointers指向兩者就好:

所以Append Node事實上也是intermediate data structure,因為不能parallel execution(因為tree unbalanced),所以勢必也要轉換成balanced tree。
不過這個轉換本身至少需要O(n),所以以上的implementation不適合達成"efficient" concatenation (至少O(logn))!因為在concatenation過程中,變成linked list,而linked list只能linear time traversal。

所以要達成O(log n) concatenation,另一個方法是 限制append node的數量,使得整體的concatenation effort能被O(log n) bounded。
這邊用到二進位的想法:二進位的數字n,但是所需要的bit數目卻是log(n),所以數字線性成長但是bit數目log成長。
以下過程省略,課程字幕實在太爛了,老師口音又常常聽不清楚,放棄!

他有一個conc tree memeber,也有一個array,以及chunkSize來記錄第一個empty array entry index。這個index就用來append element,直到array滿了以後,就expand一個新的array,並且把此滿了的array 包成Chunk node放入 conc tree。


Chunk node定義如下,功能類似Conc tree中的SingleNode:

以下又省略了,實在聽得很痛苦,直接寫作業吧!
這門課的口音和字幕帶給我很大痛苦!
combiner trait的append就是 += method,假設我們用conc tree來當作combiner的instance variable xs:

我們知道至少要O(log n) time來做append,但是有沒有辦法constant time?
事實上是有ㄟ!
不過要loose Conc tree invariance 2: 仿造 <> node,定義一個Append node:

但是不限定append node的左右children的高度差!所以以下的subtree 是合法的:

所以append很快,可以是O(1),因為只要把append node的children pointers指向兩者就好:

所以Append Node事實上也是intermediate data structure,因為不能parallel execution(因為tree unbalanced),所以勢必也要轉換成balanced tree。
不過這個轉換本身至少需要O(n),所以以上的implementation不適合達成"efficient" concatenation (至少O(logn))!因為在concatenation過程中,變成linked list,而linked list只能linear time traversal。

所以要達成O(log n) concatenation,另一個方法是 限制append node的數量,使得整體的concatenation effort能被O(log n) bounded。
這邊用到二進位的想法:二進位的數字n,但是所需要的bit數目卻是log(n),所以數字線性成長但是bit數目log成長。
以下過程省略,課程字幕實在太爛了,老師口音又常常聽不清楚,放棄!
怎麼用conc tree implement Combiner
這個combiner叫做ConcBuffer,定義如下:
他有一個conc tree memeber,也有一個array,以及chunkSize來記錄第一個empty array entry index。這個index就用來append element,直到array滿了以後,就expand一個新的array,並且把此滿了的array 包成Chunk node放入 conc tree。


Chunk node定義如下,功能類似Conc tree中的SingleNode:

以下又省略了,實在聽得很痛苦,直接寫作業吧!
這門課的口音和字幕帶給我很大痛苦!
沒有留言:
張貼留言