讀入資料
import numpy as np import pandas as pd from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer()
不過這是一個dict,還不是一個pandas dataframe。雖然Scikit-learn不需要一定使用dataframe,但這對清理資料有幫助,嘗試將之轉換成dataframe。
def to_dataframe():
df = pd.DataFrame(data=cancer['data'], columns=cancer['feature_names'])
df['target'] = cancer['target']
return df
class distribution
惡性與良性的分類各有多少呢?def class_distribution():
df = to_dataframe()
result = pd.Series({'malignant':len(df[df['target']==0]),
'benign':len(df[df['target']==1])})
return result
區分label與data
def split_data_label():
df = to_dataframe()
X = df[df.columns[:-1]]
y = df['target']
return X,y
製作75% : 25% training set vs test set
def training_set():
X, y = split_data_label()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
return X_train, X_test, y_train, y_test
train 1-NN classifier
def _1NN_classifier():
X_train, X_test, y_train, y_test = training_set()
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
return knn
使用classifier來預測
要製作input,這邊使用一個假的data,就是每個feature在dataframe的mean組成的feature vector。def predict():
cancerdf = to_dataframe()
means = cancerdf.mean()[:-1].values.reshape(1, -1)
knn = _1NN_classifier()
result = knn.predict(means)
return result
predict test set
當然我們要來evaluate estimator的好壞的話,還是要來測試test set:def predict_test_set():
X_train, X_test, y_train, y_test = training_set()
knn = _1NN_classifier()
result = knn.predict(X_test)
return result
Accuracy
最後可以檢驗此次training結果的accuracy:def answer_eight():
X_train, X_test, y_train, y_test = training_set()
knn = _1NN_classifier()
result = knn.score(X_test, y_test)
return result
這次training結果對training set以及test set中的兩種classes的accuracy如下:
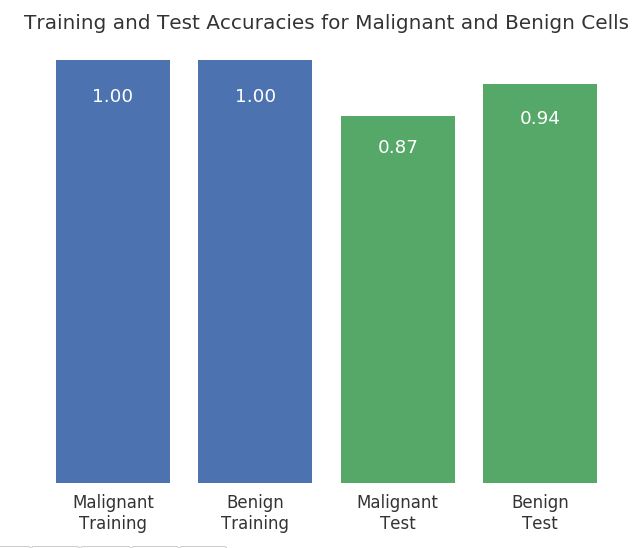
沒有留言:
張貼留言