General Guides
每個服務商(e.g. Azure / AWS / GCP ...) 都有自己的cloud patterns guide,可以generalize成以下五點:
1. operational excellence - 在設計cloud native app的時候就要考慮維運與開發的因子,透過DevOps的practice來實踐:
a. 所有東西都要自動化 - 減少人為錯誤到最低程度,配合上Infrastructure as Code (IaC),整個環境設定都是程式控制。
b. 所有東西都要監控 - 對如何持續改善有幫助
c. 自動化文件化所有東西 - 透過Swagger這類tool
d. 所有動作都是reversible - 所以IaC是很重要的
e. 設計錯誤時的處理 - gracefully fail
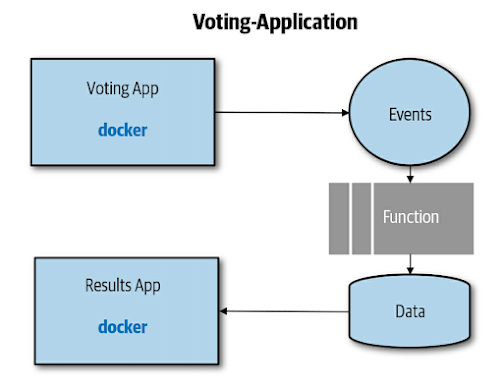
2. 資安 - 目前普遍接受的說法是cloud application比地端要安全,但還是要特別著墨,採用defense-in-depth的approach,在設計架構時就把資安納入考量。以下是一個voting cloud app:
此app採用的defense-in-depth的方向如下(假設使用container + K8s):
- 採用安全的code repository + CI整合靜態分析code安全性
- container image: 永遠只加入與expose最低限度需要的東西
- container registry: 使用private registry來存放image,需要有權限控管,以及安全性掃描image例如使用Twistlock
- Pod: container images只能從被許可的registry pull後來,每個pod要有identity才能讓其中的程式存取其他的service,再來要考慮node-node間如何安全的通訊。
- Cluster and orchestrator: cluster要放在內網還是外網,以及要把Kubernetes RBAC enabled。
3. Reliability vs Availability
reliability - application能持續運作,即便存在某些錯誤。所以application要能被設計成即便發生錯誤持續使用之外,還要能恢復正常。
availability - application能被使用在一段持續的時間內,例如多個redundant instances or replicas。
4. Scalability and cost
1. 如果不自動決定何時該scale up,則需要在一開始就支付某個規模程度的cluster of nodes,則不是很cost-effective,因為多數時間可能都資源遠大於需求
2. 如果採取自動scale up當資源不足時,則會被啟動new node (VM)的速度遠慢於啟動container的速度所困擾,這需要考慮進去。可以考慮Container as a Service (CaaS)包含Azure Kubernetes Service virtual node,或是AWS Fargate。
Cloud Native vs 傳統架構
差異包括:
1. state處理 - state包含session / application configuration等,傳統架構通常是stateful的,通常暫存放於compute instance variables,所以需要load balancer透過sticky session的方式來確保同一個session都是連到同一個compute instance。
上圖中,LB發現VM0死掉的話,會將user 導向VM1,但是原本的session data將會遺失,造成問題。
而cloud native由於compute instances是動態增減的,所以在設計之初就會朝向stateless的方向去設計,通常session data是被外部化的存放於data store,不隨著compute instance的增減被影響。如下圖:
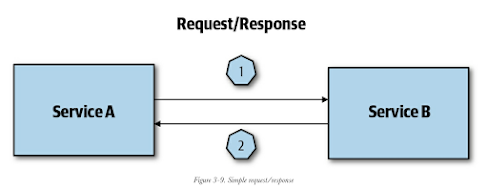
2. orchestration - 傳統架構通常使用service orchestration service來處理request,而且通常是synchronous等待的:
這樣synchronous waiting當然就有他的問題
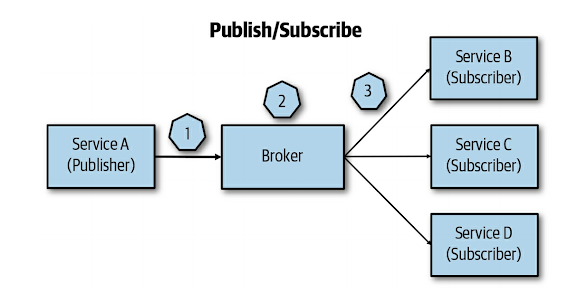
cloud native通常採用event-driven pattern來溝通,把一個request分給多個低耦合的服務來執行稱為service choreography,每個service maintain自己的state:
上圖紅色方塊就是event-driven communication component,整個流程就是所謂的service choreography。
Functions vs Services
在設計一個application之初,就會面臨要選擇一個容器化的service,還是要走FaaS?
FaaS雖然比較適合短生命週期跟獨立的tasks,但目前許多FaaS已經成熟到能讓整個application都建立在FaaS上面(e.g. Azure Durable Functions or AWS Step Functions)。FaaS比較大的限制是執行時間timeout短(不能執行長時間運算的東西)
FaaS適合以下scenarios: 平行化獨立事件 / 排程 / map-reduce / message routing。
使用FaaS也有以下要考慮的問題:
1. 一個monolithic切分成小function的複雜度
2. 有限的執行生命週期
3. 目前尚無(人)法用特異化的硬體,例如GPU
4. 由於每個function沒有state,所以所有計算都要pass in data,並且pass out data,會有較多節點的溝通,形成網路上的延遲
5. local開發不一定能成立,因為FaaS不一定有local開發環境
6. FaaS不一定比較便宜,因為節省了compute instance cost,但是又加入了networking / storage / eventing等supporting services費用。
容器化的服務沒有以上的問題,所以可以混合使用services + FaaS來達成彈性。之前提到的voting application可以在某些component使用FaaS:
這個FaaS component只負責將event發生時的某些條件,變成data放入data store,非常方便去scale up。但是要注意FaaS scales up的時候,瓶頸會發生在與他對接的系統中,例如圖中的data store,所以好的practice是data store也採用managed services (e.g. AWS RDBMS)。
此外,你應該要知道自己的application scale的特性,例如container image大的話,根本就來不及在高峰期scale up,或是你的container雖然冷啟動很快,但是她依賴的相關的service要scale up的冷啟動時間很長,也會使得高峰期(busrt scenarios)的scale up失敗。